PGStudy-GoogleBigTablePart
Big Table
- 简明定义:一个BigTable是一个稀疏的,分布的,永久的多维排序图。
如何在文件内快速查询

通过将文件中的内容按照内容分配一个一个key通过key对文件中的内容进行排序
Table = a list of sroted <key, value>
如何保存一个很大的表
提出一个概念 metadata of table —— 该表保存许多小表的索引
即 Metadata of Table = a list of Tables Table = A list of sorted <key, value>
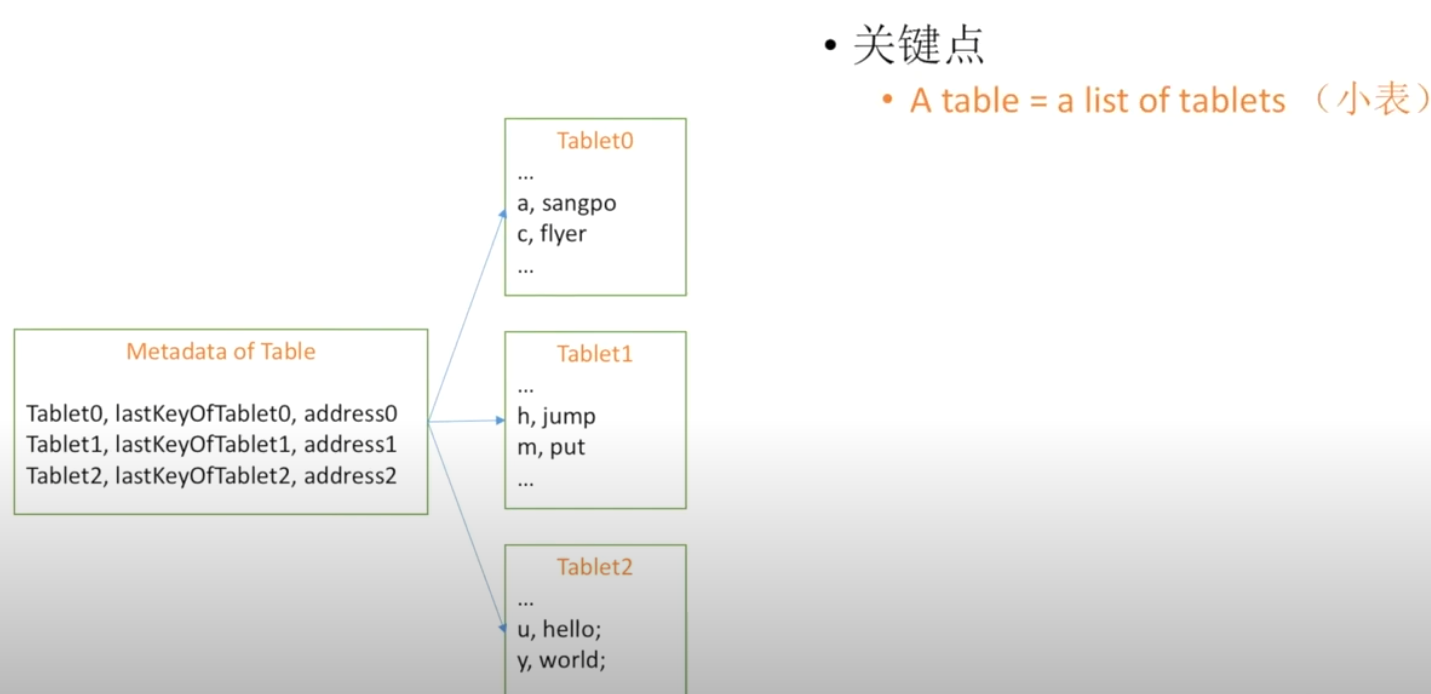
如何保存一个超大表
重复的方式,通过SSTable的方式保存数据,使Table变为SSTable的metadata
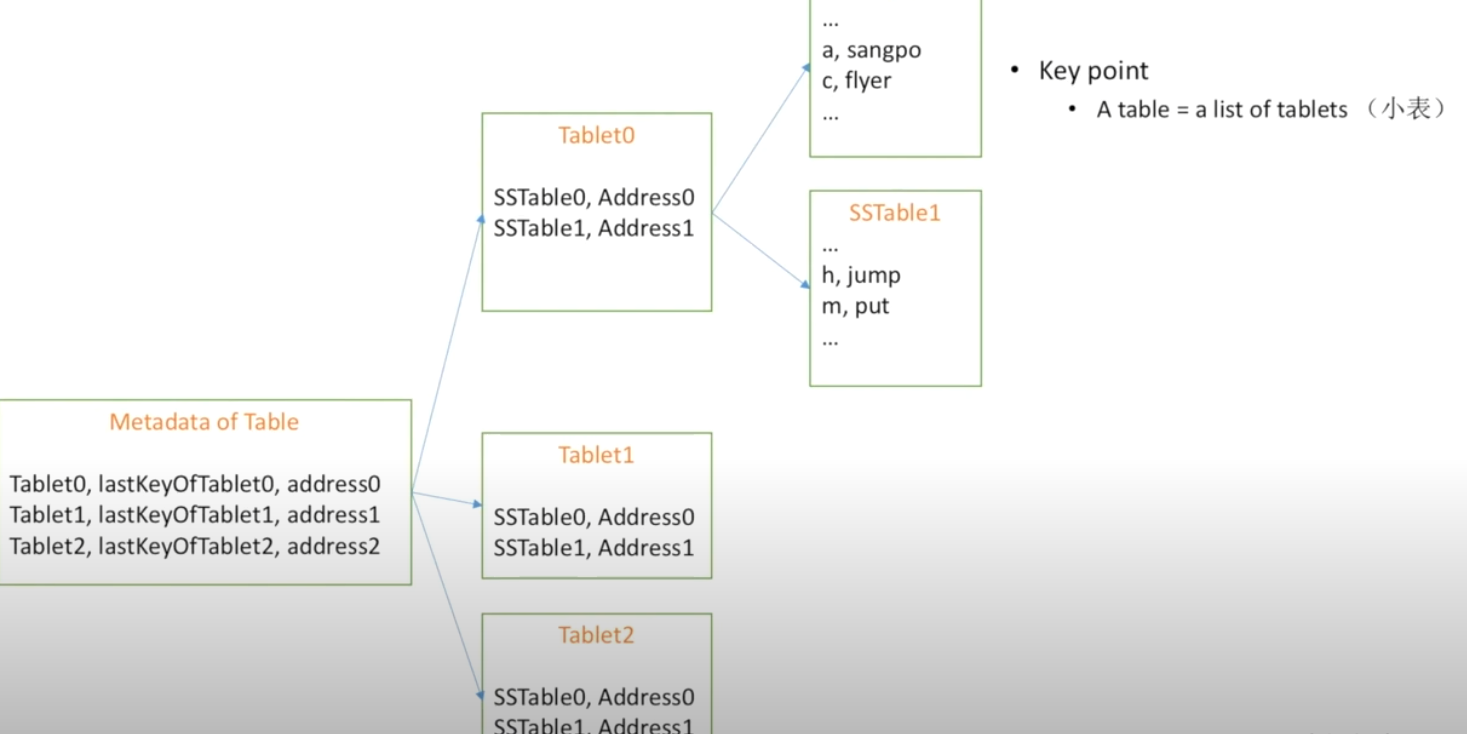
通过SSTable进一步扩大表的容量
如何向表中写数据
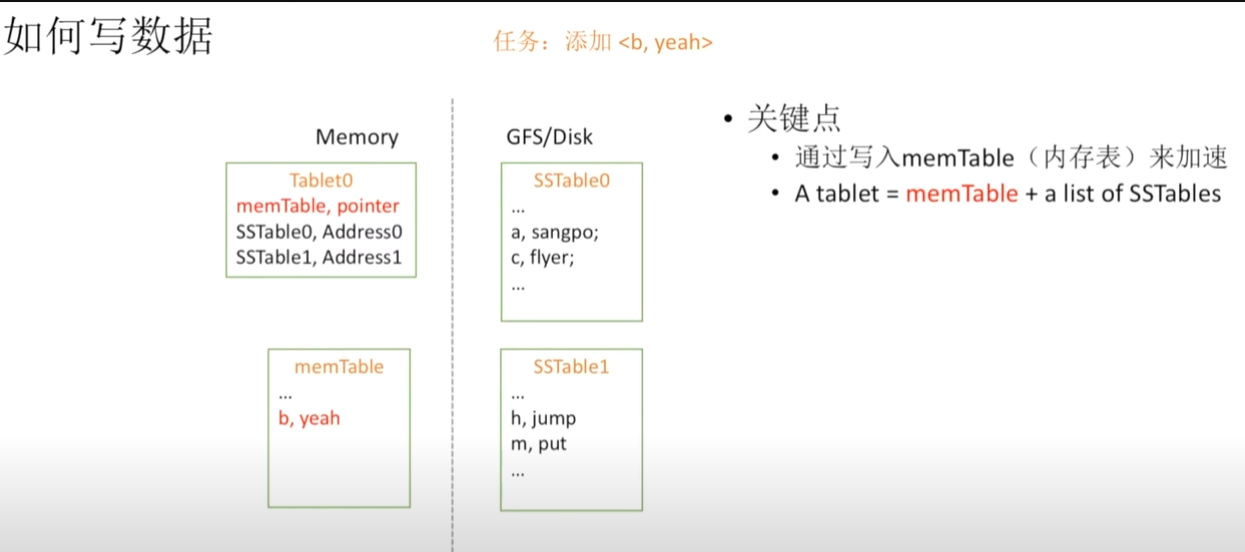 在向BigTable中写入数据时,首先在内存中建立一个小小表(SSTable)这里叫做memTable,通过该表来加速写入,注意,这里的写入需要有序,因此相对于Disk,memory才有显著的优势(它是随机读写)
在向BigTable中写入数据时,首先在内存中建立一个小小表(SSTable)这里叫做memTable,通过该表来加速写入,注意,这里的写入需要有序,因此相对于Disk,memory才有显著的优势(它是随机读写)
当内存表过大时怎么办
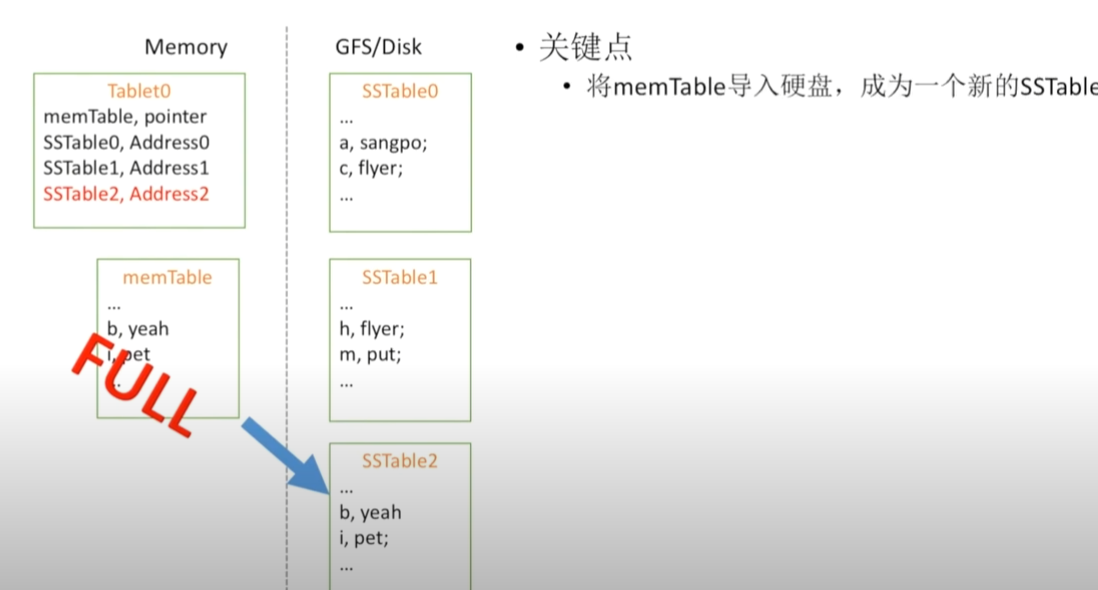
当内存表过大的情况下,将内存表写入Disk,由于这个时候是顺序读写,性能也是较好的
内存表写入时,可能会发生内存丢失
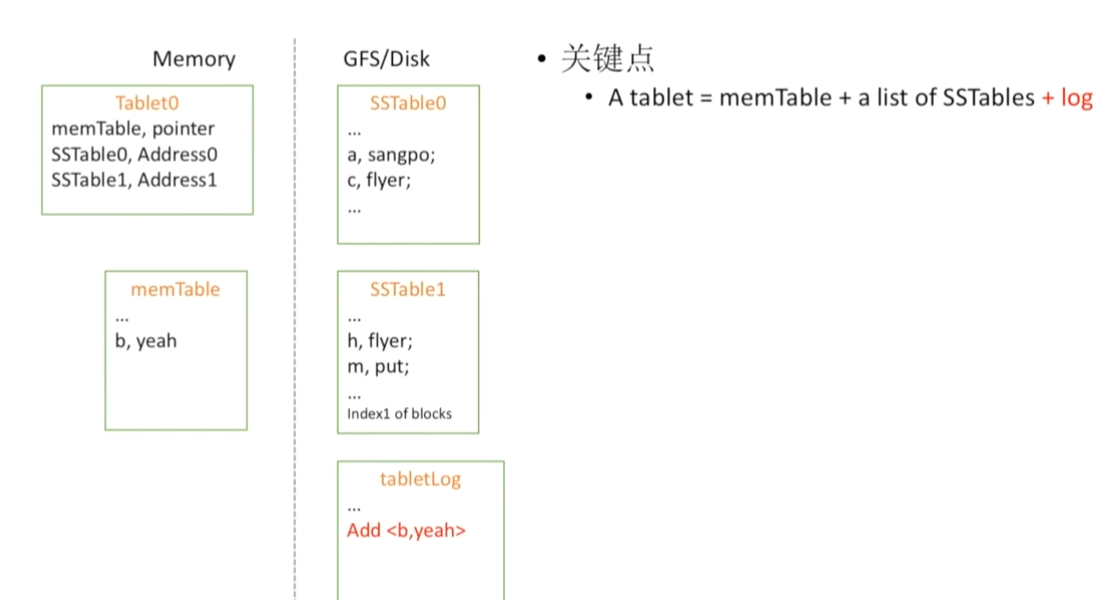
通过建立一个tabletLog来防止内存数据的丢失
如何读数据
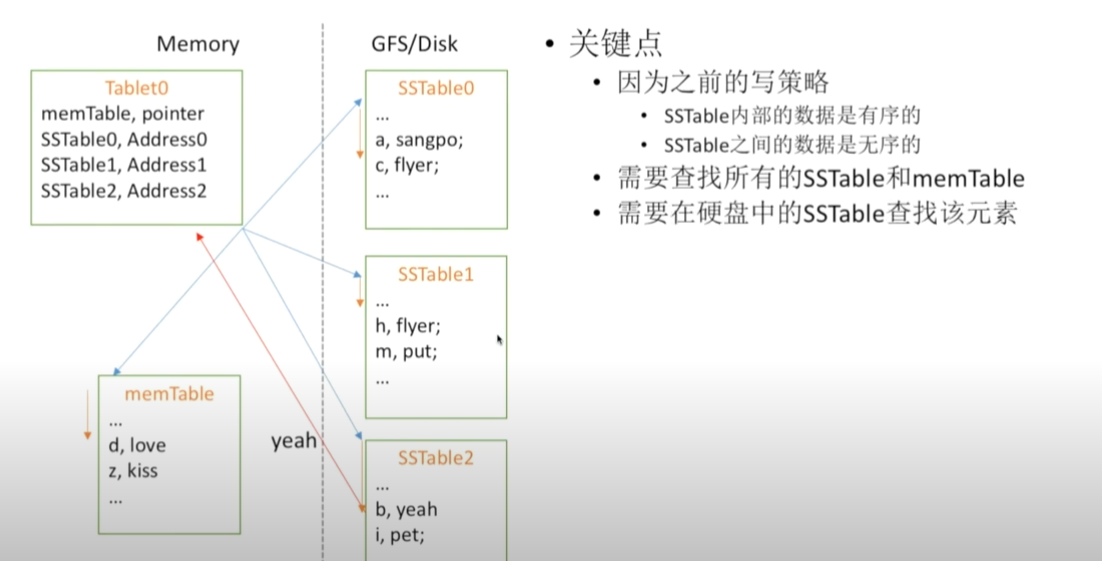
由于写数据时并未考虑表之间的键值顺序性,因此每个表之间处于无序状态,在一个表内有序,表间无序的结构中进行查找,效率是较低的。
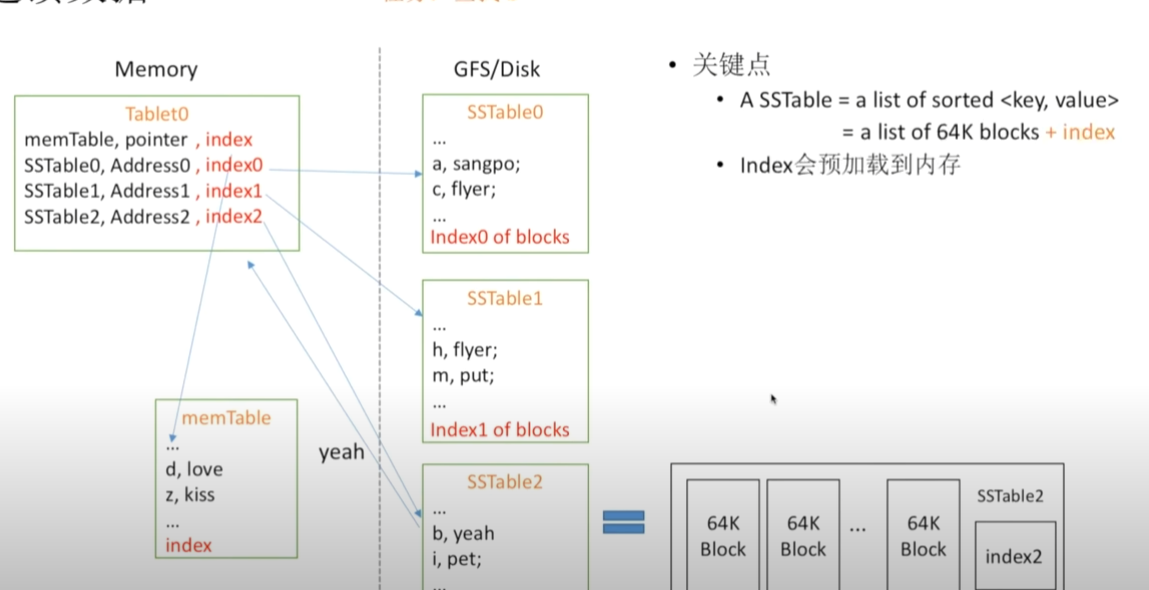
通过对小小表添加索引的方式加速内存,这样的索引可以视作多级索引,它的产生很大程度上是因为Disk中的SSTable是静态的,而该建立索引的操作减少了对SSTable中键值的地址定位开销
Bloomfilter加速
Bloomfliter的具体表现为通过很快的操作给出一个大概率某一键值存不存在于键值集合中。通过对每一个SSTable的BloomFilter建立,并在查找时优先通过BloomFilter进行查找就可以极大的提高对key的查找
如何构建Bloomfilter
Bloomfilter是一个位数组。它通过以下的方式构建
- 存入关键词时,将关键词通过多种不同的哈希方法映射到不同位上
- 将这些位变为1
如何利用Bloomfilter进行查找
- 当查找关键词时,将其通过同样的一组哈希方法映射到不同为上
- 若这些位全为1,那么则判断该关键词存在于集合中
Column Family
在Google Bigtable中,列族(Column Family)是一个重要的概念,它用于组织和存储数据。
概念
- 列族:列族是指一组相关的列,它们在逻辑上被视为一个整体。在Bigtable中,每个列族包含一组列,这些列共享相同的存储和访问特性。
- 列的定义:在每个列族中,列的名称可以是动态的,用户可以在写入数据时随时添加新的列。列族的创建是在表定义时完成的,而列可以在数据写入时动态添加。
作用
- 数据组织:列族提供了一种方式来组织和分组相关数据。例如,用户可以将用户信息的基本信息(如姓名、年龄等)放在一个列族中,而将用户的活动记录放在另一个列族中。
- 存储优化:同一列族中的数据在物理存储上是相邻的,这样可以提高数据读取的效率。通过将相关数据聚集在一起,Bigtable可以更有效地进行磁盘I/O操作。
- 访问控制:列族可以帮助实现访问控制策略。可以对不同的列族设置不同的权限,控制用户对数据的访问。
- 压缩与存储:不同的列族可以采用不同的存储和压缩策略,这样可以根据数据的访问模式和特性进行优化。例如,频繁访问的数据可以选择不压缩,而不常访问的数据则可以选择更高的压缩比。
如何将表存入GFS
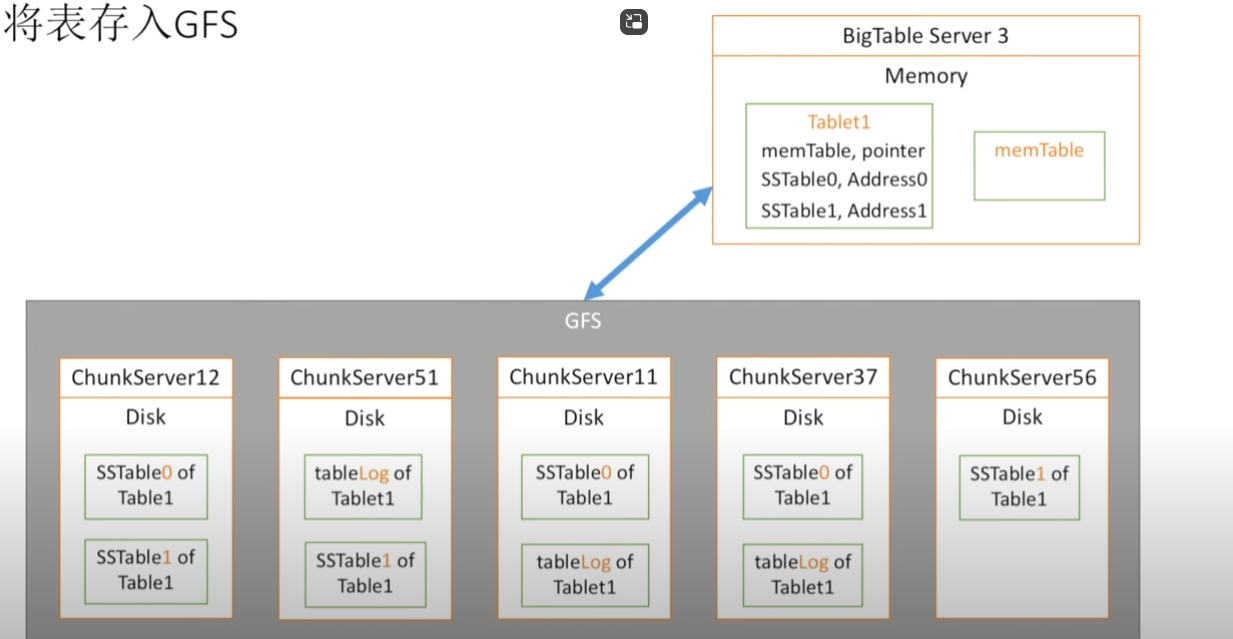
该物理视图是非常简单的,因为GBT与GFS同样以64K作为一个Block,很容易进行内存映射,同时这里表达了对GFS的“三份备份”思想的表达。
最后大观
参考资料
- Bigtable: A Distributed Storage System for Structured Data
- [译] [论文] Bigtable: A Distributed Storage System for Structured Data (OSDI, 2006) (arthurchiao.art)